04.01.2024
5min read

The Challenge of Continuous Health Assessment: Long-Term Monitoring with the Horsted Institute
How do you know if a medical treatment works?
Some medical treatments are simple to see the effect of, but how do you keep track of patients' development during a longer period? Especially if the treatment is trying to cure a symptom that can be affected by other outside factors, or if the symptom can vary from day to day.
This was one of the key challenges we set out to solve together with the Horsted Institute.
Horsted presented a case where the task was to track patients' health development closely. Mainly we had two sets of actions:
- Monitor different health aspects. Currently we track 16 types, among others the patient's heart rate, physical activities, and sleep.
- Record the experienced pain, headache, and nausea.
Wearable Tech Meets Health Monitoring: Our Apple Watch Proof of Concept
If you’re into mobile development, you likely already know that the answer to the first set of actions is straightforward - by using a wearable device. For the proof of concept, we chose to use the Apple Watch for tracking a user’s health since it tracks heart rate and physical activities. Furthermore, users are likely to wear their watch nearly all the time. It’s a great place to be for an app, to remind users to fill out a daily survey.
Since watchOS 6, it has been possible to create dedicated Watch apps, meaning, the app doesn't rely on the connectivity from an iPhone to work, though users still need an iPhone to pair and set up their watch.
This allowed us to create one app that could be installed directly on the Watch, simplifying the scope of the project slightly, so we could avoid creating a phone app and a watch app, but just keep our focus on one platform.
So, how do we then collect the tracked data? Well, the quick answer would be to upload it to a server, but to keep the solution as simple as possible and not use time to create a backend, we went for a solution where data gets packaged and sent via email using a 3rd party service. – bear in mind, this is a proof of concept.
Do you want to know more about wearable technology in healthcare? Read right here.
Journey into Apple's Health Data Hub: Permissions, Queries, and Overcoming HealthKit Pitfalls
When talking about tracking health data in the Apple ecosystem, the way to do it is by using Apple's HealthKit.
HealthKit stores a variety of different health data. Apps can request access to the data, which the user of the device then can grant or deny. If granted, the app can then start consuming the requested types of data, from here on, it’s then up to the app how to process the health data.
Requesting access to HealthKit
Health data is a very personal thing and Apple takes that seriously. Therefore, before an application can start consuming data, the application needs to ask for access to the health types that it would like to consume. As the patients are instructed in why the watch will need the access, we’ll expect that the patients will provide the access for us. If a patient denies access to the data, the app would still be able to run, but the collection of health data - which is the main purpose of this proof of concept - would not work.
Data wise, there’s multiple types that can be recorded, in this sample, we’re mainly using the two following:
- Quantity type
- Category type
Quantity type is counting things, like “how many calories were burned”, “the number of steps”, “heartbeat count”, and likewise.
Category type can be expressed as an enumeration. Sleep is a good example of this, like “inBed”, “asleep”, and “awake” - well defined states.
So, now we know the data structure, how do we then ask for permission to get data?
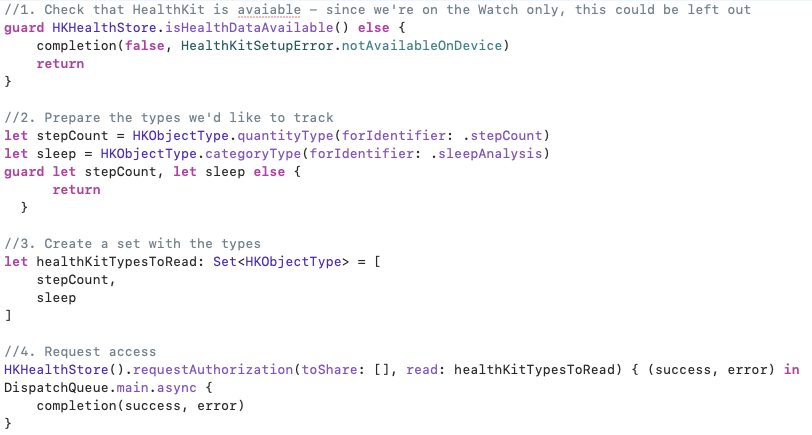
First, we check if health data is available. We could leave it out for this prototype though since the only place where health data isn’t available is on iPad. But in general, it’s good coding practice to check, things could change down the line.
Then we ask for permisson the types we’d like access to, in the example, we’ll ask for permission to read “step count” and “sleep analysis”.
Consuming HealthKit records
Now that we have access to health data, it’s time to query some data. First, we create a predicate and pass the date range we’re interested in.
Then define how we’d like the data sorted, in this case by end date.
With the sort-descriptor and predicate, we’ll create a query, for the sample type we’re interested in. Finally, we’ll call our HealthStore to execute the query.

HealthKit “pitfalls”
When requesting samples, the response will contain all data recorded within the given predicate. This means that if the user also carried around their phone e.g. counting steps or measuring sleep, you might see “duplicated” data entries, for the periods when the user was both wearing the watch as well as having the phone in their pocket.
Some sanitisation of the data is therefore necessary, either on the watch/phone or when the data has been uploaded to a server for further processing. Otherwise, some people could end up having slept for 25 hours a day. And while that may sound nice, especially for someone like me with small children, it's not reality.
For data processing, we decided to let the ‘analysts’ handle sanitisation. That means, that the analyst will receive all the samples, including duplicated trackings where e.g. both phone and watch have made a recording of the same.
By moving the data processing to the very final step, we allow the analyst to run algorithms on the same set of data multiple times, without losing data on the way.
Optimising Health Data Sharing: Apple's TabularData Framework and the Power of DataFrame
As previously mentioned, we’ve left out the requirement for a backend, which means we don’t have a central place to store all the data. Since the number of participants in the testing phase is relatively limited, we’ve tried to use as simple and flexible tools as possible.
One way to structure, sort, and filter data, which many people can easily do, is to use a spreadsheet like Excel. A common, simple way to share data that can be opened across multiple spreadsheet editors is CSV (Comma Separated Values). However, making sure that the column separator in the CSV is correct for columns and escaping potential special characters for the data is done right can be a challenge, due to character sets and character encoding.
In 2021, together with iOS 15, watchOS8, and macOS 12, Apple introduced a framework called TabularData. According to Apple, the framework is intended to Import, organise, and prepare a table of data to train a machine-learning model. Though we’re not doing any machine learning in this proof of concept, we’re organising and preparing tables of data, and for that, TabularData works great.
A DataFrame is a structure that arranges data in rows and columns. Each column is defined by the Column<WrappedElement>, where WrappedElement defines the data-type that goes into the row for the column. This gives you type-checking when adding a new row of content.

When all data has been added to the DataFrame we can save it an CSV file:
Now that we have the data saved as a file we control, the last step is to make sure the data gets sent to the analyst.
From Raw Data to Real-world Impact: Are We on the Right Path?
We’ve managed to get health data from a select group of people and monitor their development over time. The development was done in a way where we used as few resources as possible, limiting the complexity of the project as much as we could. We’ve cut corners by not using a backend server, keeping development to a single very basic WatchOS app. Data formatted with DataFrame to give analysts an easy-to-use format that can be opened directly in, for example, Excel.
Does the treatment for the patients then work? The first tests were carried out with the doctors and the team around the project, to verify the flow of data.
The second test round is carried out with a select group of patients, who each received an Apple Watch with the TestFlight app installed.
At the time of writing, the second test is still being carried out and it looks promising. We have proven that we can build a simple tool that can be part of solving the challenge of seeing if a medical treatment works for the patient.